
Review written by Andy Jones (COS, G3)
In many countries, cameras are nearly ubiquitous in public society. When you go to public places — such as stoplights, stores, or hospitals — a photograph is often taken of you.
When these photographs are collected into large datasets, they can be useful for developing machine learning (ML) solutions to real-world problems. For example, automated analysis of stoplight photographs could improve traffic flow, and examining customer behavior patterns in clothing stores could improve the shopping experience. However, a large fraction of these photographs contain personal identifying information, such as faces, addresses, or credit card numbers. These photos prompt concerns about the privacy of the individuals identified in them. Thus, at first glance there appears to be a tradeoff between using large datasets of images to train ML algorithms and protecting people’s privacy. But what if the people in these images could somehow be anonymized to protect their privacy, while the images could still be used to build useful ML models?
This was the central question pursued by a group of Princeton Computer Science researchers in a recent paper led by graduate student Kaiyu Yang. In collaboration with colleagues at Stanford, Yang et al. tested whether it is possible to anonymize people’s identities in images without diminishing the ability of ML models to learn from these images for other purposes.
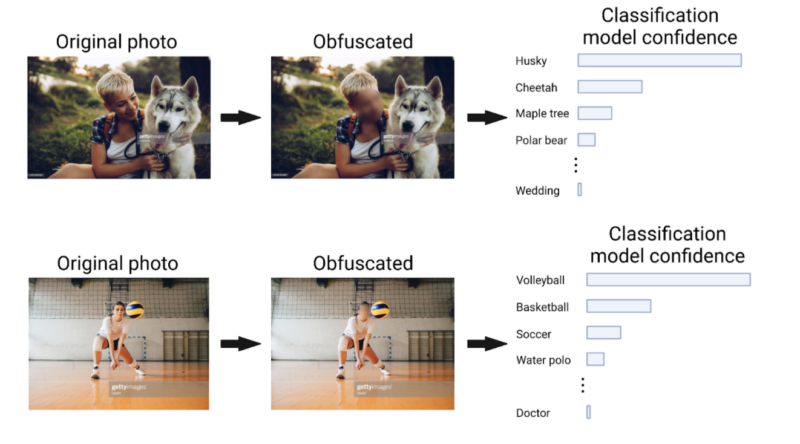
The authors focused on one method for anonymization in particular: face obfuscation and blurring. They asked, if a face is blurred or removed from an image in order to protect a person’s identity, can an algorithm still identify the other objects or scenes in the image? To a human, this question seems silly: if we are looking at an image of a woman playing volleyball, but her face is blurred, surely we can still recognize that she is playing volleyball. However, ML algorithms operate quite differently from the human brain, often relying on unexpected cues in one part of an image to make inferences about another part of the image.
“An important distinction to make is what a human thinks is a reasonable way to detect an object versus a machine,” says Yang.
Thus, it’s not clear whether an ML algorithm would still be able to identify a volleyball game after a woman’s face is blurred.
To answer this question, the researchers used a large public dataset called ImageNet, which has served as an important catalyst for many advances in computer vision and ML in the last decade. These images were collected from online image search engines, such as Flickr and Google Images. Of the approximately 1.4 million images in ImageNet, about 243,000 (or 17%) contain faces. In order to simulate a privacy-aware version of the dataset, the authors created a version of this subset of the dataset in which all faces had been blurred out, effectively obscuring the identity of each person.
Using both of these datasets (the original and the copy with blurred faces), they trained an ML model called a deep neural network to classify each image into one of a number of predefined categories, such as “volleyball”, “beer bottle”, and “barber chair”. The categories — which were defined as part of the original ImageNet construction — span a wide range of image types. The authors then checked whether the algorithm performed substantially worse when trained using the images with blurred faces, or whether the blurring had no effect on accuracy.
They found that the performance with the blurred images was only slightly worse than the performance with the original images (the accuracy only declined by 0.68%). This finding was surprising because human faces tend to provide salient image features that are useful for ML models to classify images. Without these faces, it appeared that the ML models could still perform well, with an accuracy of 69.37%, by using other features in the image.
The authors also performed an experiment in which they trained a neural network to classify each image in the full ImageNet dataset (both those containing obfuscated faces and those without any faces), and then fine-tuned this neural network to a set of other ML tasks, such as object detection (e.g., localizing a cat in an image) and face attribute classification (e.g., identifying whether a person has glasses or is smiling). This procedure, known as “transfer learning”, is a common strategy for leveraging broad patterns found in large datasets such as ImageNet for performing tasks on other, smaller datasets. They again found that the performance of these algorithms was not hurt when using the face-obfuscated images compared to the original images. This finding was especially remarkable for the face attribute classification task, which explicitly relies on face-related features.
The authors’ findings provide one piece of evidence that advances in ML do not have to come at the cost of personal privacy. Yang hopes that this work pushes researchers to be more conscientious of privacy concerns both when analyzing large image datasets and at the time of dataset collection.
“In the past decade, we've seen lots of datasets that have fueled ML research, but the collection of these datasets has been unregulated,” said Yang. “At the time [of collection], the ethical implications of these technologies were not considered. In the future, hopefully we can make the community pay more attention to the ethical impact of the dataset.”
The original article was posted as a preprint to arXiv in March 14, 2021. Please follow this link to view the full version.