
Review written by Rohini Majumdar (PSY)
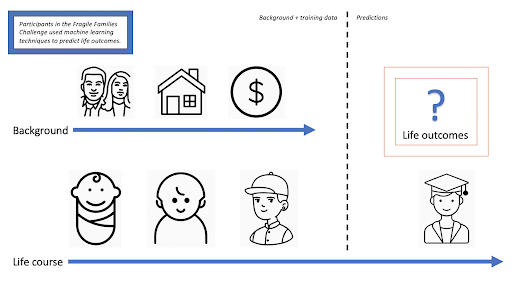
Research on life trajectories is one of social science’s most popular exports to policy making. Predictive models for specific life outcomes have been applied to a number of settings, including criminal justice and child-protective services. Despite the real-world relevance and far-reaching impact of this research, not many high-quality datasets exist to support it. The Fragile Families and Child Wellbeing Study (FFCWS), however, is one such enterprise by Princeton’s Center for Research on Child Wellbeing and the Columbia Population Research Center. Over 900 studies have used the FFCWS’s rich longitudinal data, which follows the families of almost 5000 babies born in major US cities around the turn of the millennium. Most of these children were born to unmarried parents, putting these families at a greater risk of splitting up and living in poverty compared to traditional families. Although life trajectory research has been used to inform policy, whether it can also be used to accurately predict specific life outcomes for individuals remains undetermined. To find out, Princeton Sociology’s Matthew Salganik, Ian Lundberg, Alex Kindel, and Sara McLanahan spearheaded the Fragile Families Challenge (FFC), a mammoth scientific mass collaboration based on a research design called the common task method.
Popular in machine learning, the common task method involves recruiting a diverse group of researchers to complete the same prediction task using their choice of prediction technique on a given dataset. A portion of said dataset is withheld in order to assess the accuracy of the predictions made by the various research groups. This design produces very credible estimates of predictability and leaves no room for concerns related to the limitations of any one researcher or method. Ultimately, 160 teams of researchers participated in the FFC. The approved researchers had access to five waves of background data from the FFCWS, collected at birth, and ages 1, 3, 5, and 9 of the aforementioned children. Half of the 6th wave of data collected at age 15 was withheld, i.e., the teams did not have access to these data. The other half, however, was made available to them as training data. Their challenge, therefore, was to generate predictions for the withheld data from the 6th wave using the available background and training data, with absolutely no constraints on what prediction techniques they could use. While the 6th wave of the FFCWS includes as many as 1617 variables, the organizers of the FFC chose six outcomes to focus on: child grade point average (GPA), child grit, household eviction, household material hardship, primary caregiver layoff, and primary caregiver participation in job training. These outcomes were chosen to ensure a variety of different variable types (binary vs continuous), substantive topics (e.g., academics, housing, employment), and units of analysis (e.g., child, household, primary caregiver).
Upon comparing the 160 submissions to the withheld data, Salganik and his colleagues discovered that despite the fact that the FFCWS data included thousands of variables meant to help scientists understand those families, even the very best predictions were not actually very good. Notably, although the best submissions often employed complex machine learning methods, they were only marginally better than a simple benchmark model using linear or logistic regression using just four predictor variables chosen by a domain expert. Further, the diversity in prediction techniques did not equate to very diverse predictions. As the authors explain, “the submissions were much better at predicting each other than at predicting the truth”. In essence, the specific technique used to generate predictions did not matter very much.
Owing to the design of the FFC, the low predictive accuracy across teams is, of course, not attributable to any shortcomings of any one researcher or method. This study’s results warrant a closer inspection of life trajectory predictive models used to inform important policies. Insofar as we measure the degree of our knowledge of the life course by our ability to predict it, the FFC has demonstrated that our understanding of child development and life trajectories is quite lacking. Beyond the myriad ethical and legal considerations associated with using low-accuracy predictive models in policy, this also brings into question the absolute level of predictive performance that is even possible for some life outcomes, despite the availability of rich datasets or the use of complex machine learning models. The authors recommend that policymakers give deeper thought to whether the level of predictive accuracy achievable in a given context is appropriate for that setting, and whether simple models or domain experts might suffice or sometimes outperform more costly complex models.
“There are important research questions that we can address collectively that none of us can solve individually,” said Salganik upon being asked about organizing such a large-scale scientific collaboration, which he describes as both exhausting and energizing. Salganik and his colleagues are continuing research to understand why the life outcomes were so difficult to predict. Current questions include whether there were important but unmeasured variables, or whether low predictability is to be expected for life trajectories. In some ways, “this mass collaboration really raises more questions than it answers,” says Salganik.
The original article was published in PNAS on March 30, 2020. Please follow this link to view the full version. Also check out the Fragile Families Special Collection in Socius (a new open access journal from the American Sociological Association), which includes additional article contributions from participants of the FFC.