
Review written by Shanka Subhra Mondal (ELE)
In recent years, machine learning (ML) has become commonplace in our software and devices. Its applications are varied, ranging from finance and marketing to healthcare and computer vision. ML already has the ability to out-perform humans on many tasks, such as video game competitions and image/object recognition, to name a few. At a high-level, ML comprises a set of algorithms that rely heavily on data (training data) to make decisions about another set of data (testing data) that it has not previously encountered. One of the sub-fields of computer vision where machine learning has proven particularly useful is in image classification, where the goal is to categorize objects in a given image. While this task might sound easy for humans, it can be challenging for an algorithm, particularly when the picture is blurred, not properly illuminated, or noisy. Robust image classification is not an easy task.
Historically, humans have been far superior to machines in robust image classification. This has been particularly true when images are sampled from previously unseen categories or attacked with adversarial conditions (Geirhos, 2018). Often referred to as “noise attacks”, these adversarial conditions are inputs specially designed to fool a machine learning algorithm. In a collaboration between Princeton’s Computational Cognitive Science Lab and Computer Science Professor Olga Russakovsky’s lab, Peterson et al. (2019) attempt to bridge the gap between machine and human image classification ability.
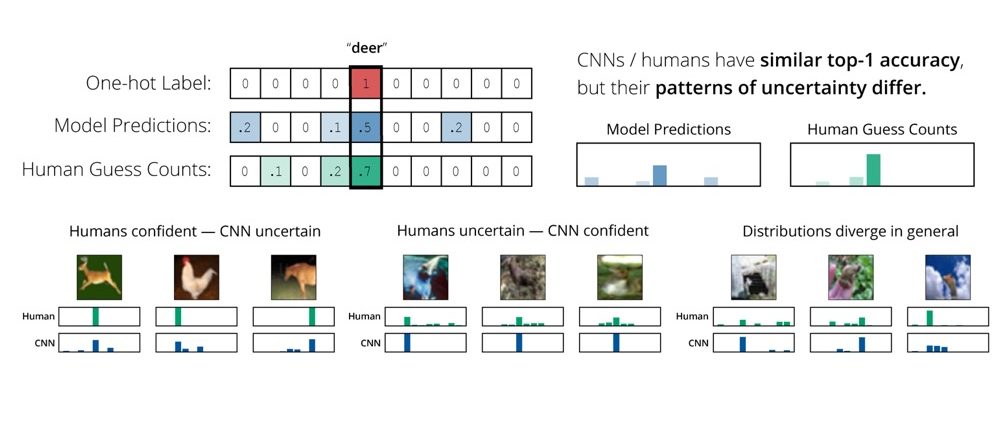
Prior to this work, there were already a number of machine learning-based algorithms available to classify image-based data. In a standard model, an image is associated with a label that refers to what the image is of (e.g., cat, dog, or airplane). Normally, ML algorithms make use of these labels (which are considered a part of the total data) in vector form. Each element of this vector is zero except for a single representative element encoded as one, which carries information about the image’s class (e.g. a “1” in position 3 could signify an “airplane” label). These types of labels are normally called hard labels. However, these labels are fixed and only capture a finite amount of information about the image. In other words, hard labels may capture that an image is an airplane, but they do not store any information about whether the airplane is more visually similar to a helicopter or a dog, for example. In Figure 1, we can see how humans and existing ML models differ in their choices.
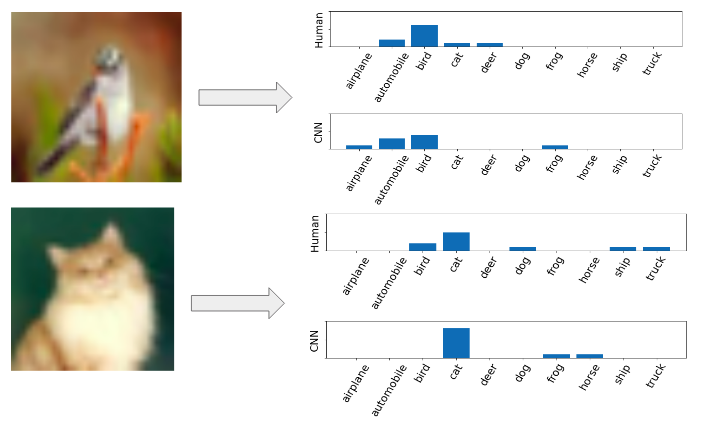
Peterson et al. (2019) introduce a more generalized model that is well-equipped to classify images. The model does this by capturing a distribution of human confidence for each label. This encoding might look something like: 40% of people classified a particular training image as an airplane, while 60% classified it as a helicopter. To capture a distribution over labels on a large scale, Peterson et. al. collected over 500k human classification judgements via Amazon Mechanical Turk, a crowd-sourcing website. Participants were asked to categorize each image they received by clicking one of the 10 labels surrounding it. They were asked to do this as quickly and accurately as possible (with no time limit). Label positions around the image were shuffled between candidates. Every 20 trials, an obvious image was presented as an attention check, and participants who scored below 75% on these were removed from the final analysis. On average, the authors collected 51 judgments per image on a total of 10k images. From these classifications, they created a probability distribution over the 10 labels based on the frequencies of the participants’ answers for each image. They termed these probability distributions soft labels.
Using these so-called soft labels (rather than hard labels), the team was able to achieve superior accuracy in predicting the classes of images that did not belong to the same distribution as the training images. In fact, the increase in accuracy grew as the distributions became more dissimilar, signifying an improvement in generalization.
To show that creating any random probability distribution over the classes is not sufficient to improve the accuracy to the same degree, Peterson et al. created and tested a number of baselines. The team also showed that using soft labels provides superior robustness when noise is intentionally introduced into the images. This is because these soft labels not only capture human category uncertainty, but also indirectly contain information about the structural similarity of images. Interestingly, Peterson et al. (2019) found that the bulk of human uncertainty is concentrated in approximately 30% of the images. Soft labels are especially useful for this subset of widely uncertain images. Overall, this novel approach of incorporating human uncertainty into ML models results in highly robust image classification, paving the way for computer vision tools that can perform on par with their human counterparts.
Joshua Peterson, co-first author and currently a postdoc in the Griffiths Lab noted that “We are currently exploring integration of other types of human behavior into the training of deep neural networks, such as typicality ratings and reaction time, which may be easier to obtain and apply to a broader range of data.
The full version of the paper is available here. It was presented at the International Conference on Computer Vision 2019, South Korea and published in the conference proceedings.
References:
Geirhos, R., Temme, C. R., Rauber, J., Schütt, H. H., Bethge, M., & Wichmann, F. A. (2018). Generalisation in humans and deep neural networks. In Advances in Neural Information Processing Systems (pp. 7538-7550).